gpt-3.5-turbo has a score of 68/1823 playing 20 questions with itself
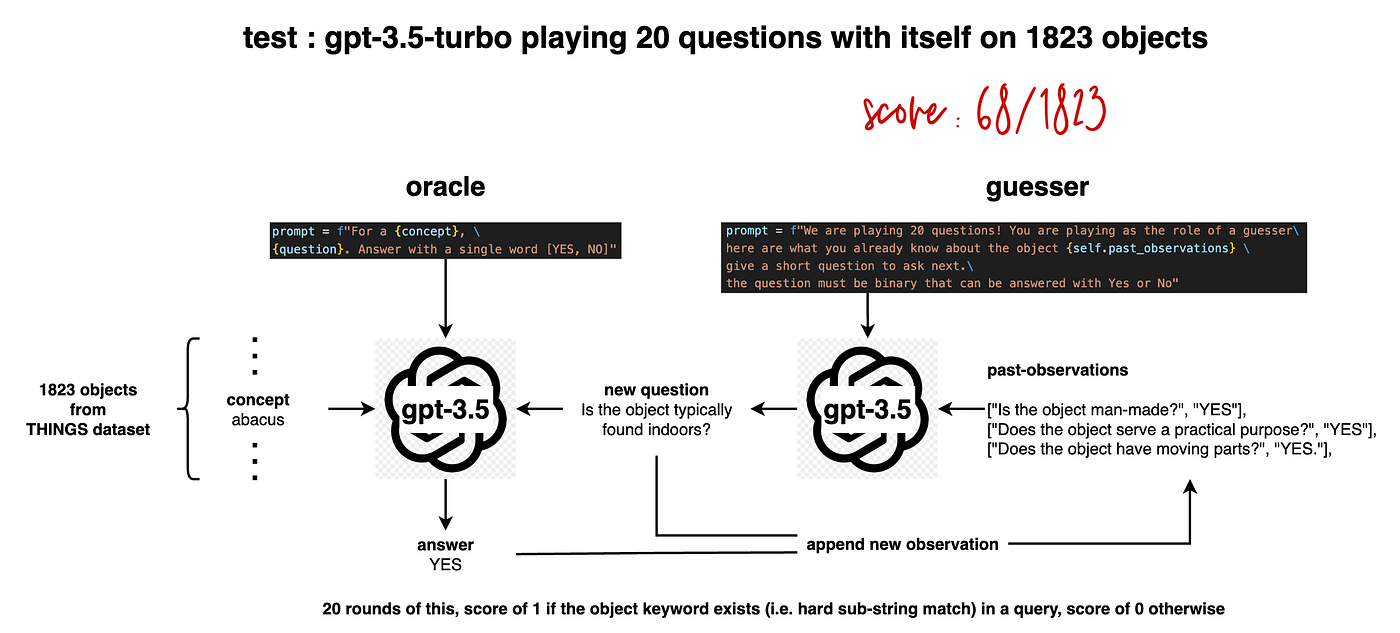
Browse all the roll-outs at this webpage. The project and the blog are low fidelity. This is by design, as the point I’m making is simple:
20 Questions (and other interactive, self-play tasks) is worth looking at in evaluating LLMs.
however, it is definitely the case that I will miss some nuances or make mistakes. please correct me using the github project (1823 game roll-outs, code, and the set of objects) as a reference point, thanks!
20 Questions as a benchmark
the complexity of 20 Questions
20 Questions forces the guesser to be cohesive in a long chain of yes / no predicates. You want an actually difficult and consistent world model? This is a good one that is combinatorially complex.
states: Each question is a sentence, each answer is a yes/no boolean. In 20 questions, the full state space is: (|#sentences|*2)²⁰
actions: Each action is a new question, the action space is: |#sentences|
policy: 20 Questions forces the player to ask intelligent questions — in the face of this cohesive, long chain of yes / no questions. The complexity of the agent is: (|#sentences|*2)²⁰ → |#sentences|
or roughly just (|#sentences|)²⁰. Assuming each sentence is about 50 characters, (26⁵⁰)²⁰ = 26¹⁰⁰⁰ ~ 10¹⁰⁰⁰. Assuming we’re playing a version of 20Qs that is “open ended”, where any word can be the hypothesis, and any question (not just scripted ones) can be asked.
Let’s ask for the complexity of Chess

10⁵⁰. I’d trust it
Let’s ask for the complexity of Go

10¹⁷⁰, I’d trust it.
Let’s ask for the complexity of 20 questions:
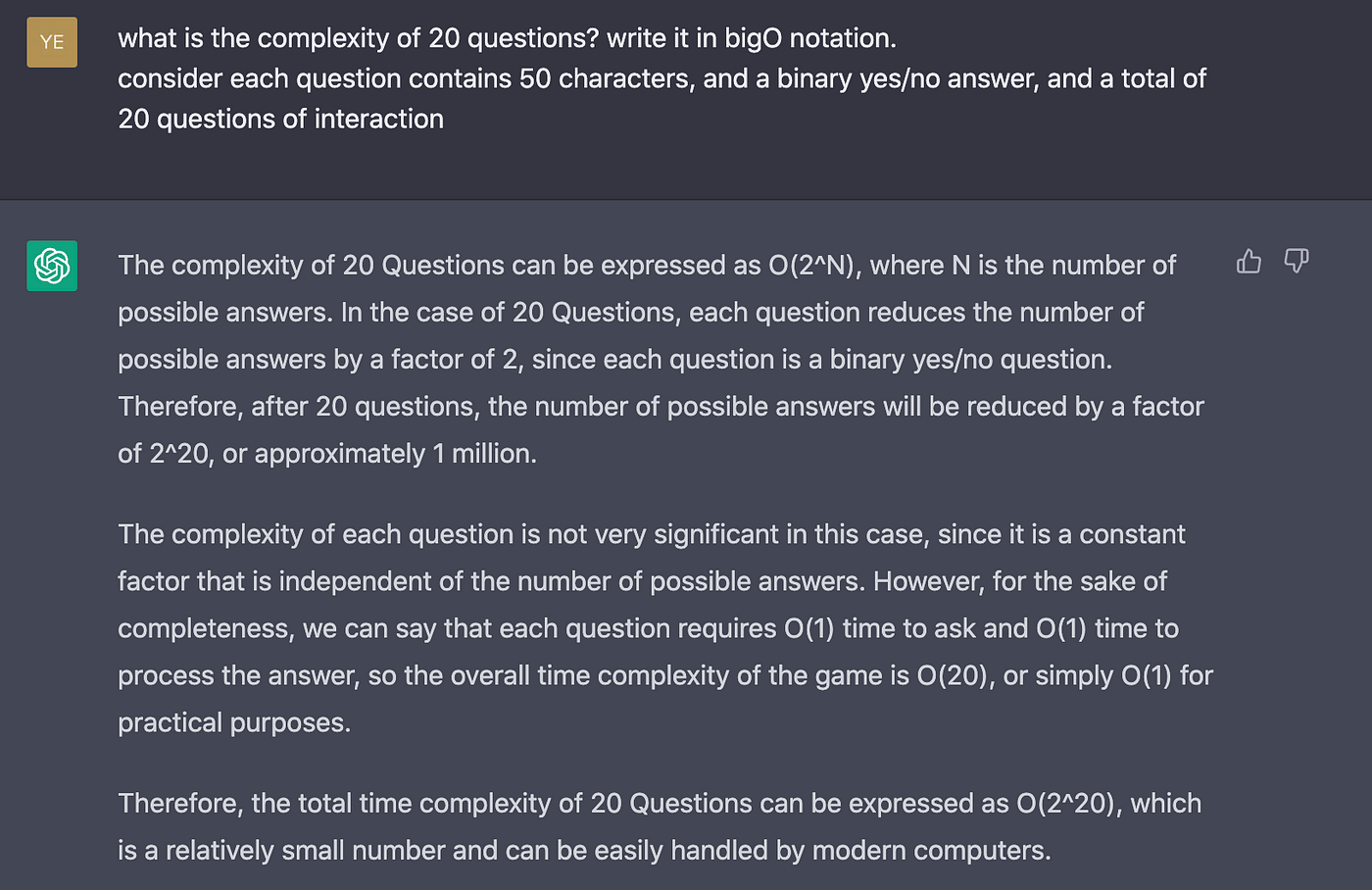
Ah the hubris.
20 Questions somewhat resists contamination
As every play is different, it has the same properly like Go, where memorizing existing playbooks will not work. It is similar to a recent Yann Lecun picture.

20 Questions tests internal consistency
20 Questions is a kind of self-play, and thus similar to inception loss where a model internally encode-decode across different representations, and the roundtrip consistency is measured.
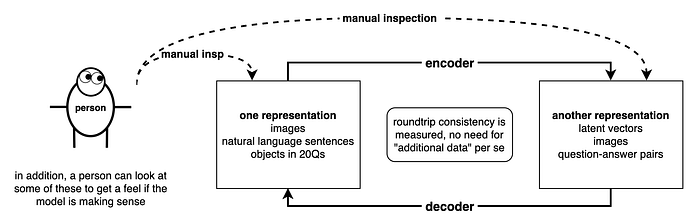
analysis of results
A proper analysis will involve playing 20 Questions on the same set of concepts with humans, and compare the human-rollouts with the machine-rollouts, which I did not do. I’d encourage you to look at the raw data and form your own opinions and hypotheses. Until then, here’s some observational analysis that’s not statistically meaningful.
as an oracle, LLM frequently give incorrect answers
For instance, on “abacus” the oracle stats that, [“Does the object produce sound when in use?”, “NO”] which is untrue if you had ever played with one, those things are more clanky than green switches. I believe there are many more examples in the rollouts if we’d take a look.
as a guesser, LLM tends to waste turns
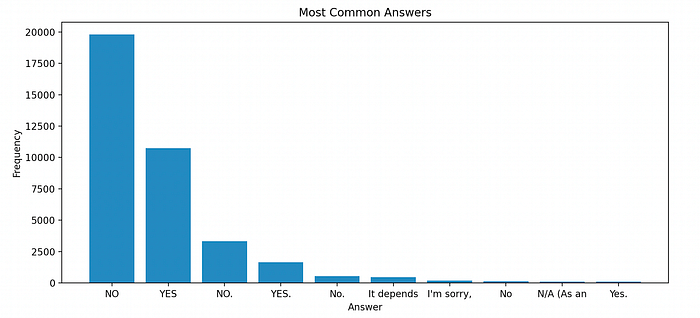
The answers are clipped to 10 characters, to prevent accidental leaks of the hypothesis. For instance, an answer “It depends on the kinds of apple you’re thinking of” will leak the hypothesis “apple” to the guesser. But overall, it is a reasonable distribution and we haven’t triggered the “I’m sorry as a large language model …” guardrails too much with our prompts.
I do not know the statistics for human players, but from personal experience, a typical 20Questions game consists of trying very hard to get the oracle to say “Yes” to a question, then quickly converges onto an answer. The over-abundance of “YES” may indicate LLM are “wasting turns” by re-confirming what it has already known. Here are some anecdotal evidence of turns wasting in a few roll outs:

As you can see, there are plenty instances of the guesser asking question which the answer would’ve been already obvious, such as asking if a non-mammal would have fur, or asking about “hard plastic or metal” again, despite having it answered previously already. It is quite possible this behaviour can be curtailed with better prompting, maybe with self-reflection or similar techniques.
situation puzzles as 20Q^k
What about Arkinator? Well yes, you can algorithm for 20 Questions with scripted questions that were selected ahead of times. Enter situation puzzles. A situation puzzle is like 20Questions, except instead of 1 word concept, it is an entire situation of multiple sentences. It will be difficult to have an efficient algorithm that plays a situation puzzle.
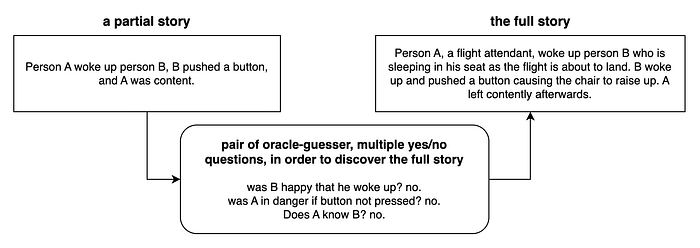
Current performance of LLM on situation puzzles are poor.
Timed Turing Tests
One dimension of Turing Test that is often omitted in the public zeitgeist is the notion of interaction time — “how long can a machine sound intelligent when interacting with a human, as a function of time?”
captcha in a few seconds. chat-bots in a few sentences. gpt4 in a few paragraphs. As AI makes progress, the time (a proxy of efforts) it takes to evaluate whether an AI system is capable will increase. And increasingly, the test will have to be interactive and dynamic, instead of relying on a fixed corpus of existing tests.
Currently we’re over-reliant on static / stationary test sets that are plastered all over the internet. This needs work.
what’s good to try next ?
some ideas here

story of how we got here
(for those who care)
When I was going to neurips 2022 I sat next to a musician in a flight. He was really intrigued with “wow there’s so many nerdy ppl on the flight rn”. I explained that we were all going to a nerd mecca, and that we’re all researchers. He expressed intrigue in AI, especially self-driving cars as his buddy was an Uber driver. I explain to him what kind of problems AI systems can do, and what kind of task they still struggle with. The task I had chosen was a situation game. I played a game with him and after 15 minutes of struggles he was able to guess that the man had hiccup. I told him that computers currently would suck at playing this game.

At New Orleans, I played a situation game (that I made myself) with my friend Leo. The full story is: “Person A, a flight attendant, woke up person B who is sleeping in his seat as the flight is about to land. B woke up and pushed a button causing the chair to raise up. A left contently afterwards.” The prompt was only “Person A woke up person B, B pushed a button, and A was content.”. Leo was able to solve this puzzle after 15 minutes of pain. I remarked that GPT would be horrible at playing this game, and Leo said that it would be really cool to have GPT play this game against itself.
Later on I found out that BIG-bench had a benchmark on 20 Questions in the style of self-play. I had always been a fan of 20 Questions, and arguably, testing on 20 Questions is simpler than a situation game — one only had to think of a word rather than an entire scenario. With everyone talking about gpt4 and the boundary between what a machine can do vs what a human can do becoming more blurry, I thought I join the fiesta as well.
— evan, 2023–03–27
follow me on twitter for more fun stuff: https://twitter.com/evanthebouncy
few logistical notes for myself
running the experiments: over night, set up time of 4 hours. writing the blog, figures, 8 hours. operationally this took 12 hours to do.
